OpenSource4You is a community actively contributing to large-scale open source software projects in Taiwan. I will be hosting the Airflow Mandarin Meeting at the following time and location:
If you’re interested in Airflow’s latest technical developments or contributing to Airflow itself. Welcome to join our Airflow meetings!
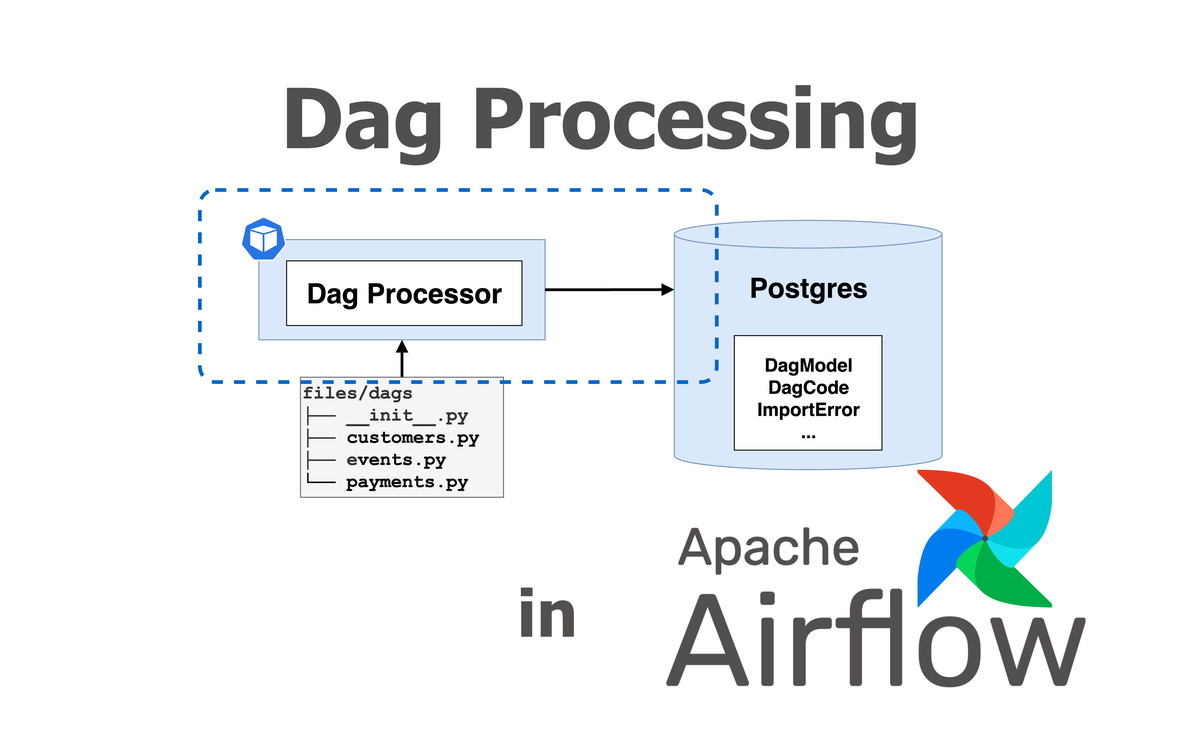
How Are Python-Written Dag Files Parsed by Airflow?#
This article provides an in-depth exploration of Airflow 2’s Dag Processing mechanism. Airflow 3 involves core details of AIP-72 TaskSDK. So we’ll focus on Airflow 2’s Dag Processing mechanism for simplicity!
Whether it’s Airflow 2 or 3, both involve the following core concepts:
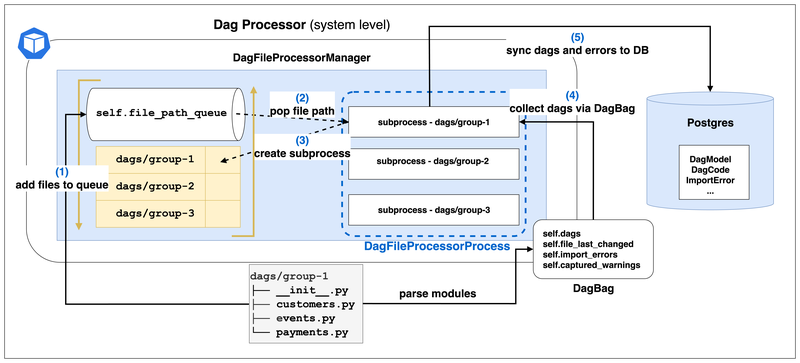
DagFileProcessorManager
DagFileProcessorProcess
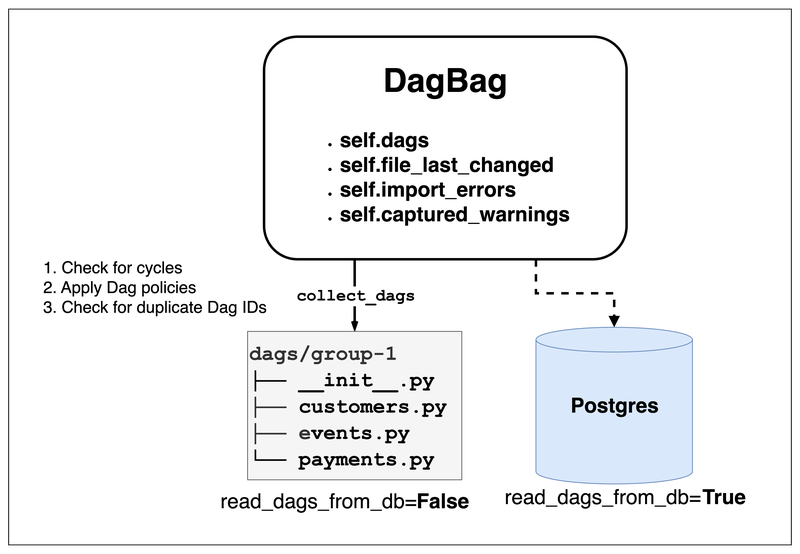
DagBag
Next, we’ll explain these concepts from an overall perspective, then dive deeper into the details of each core concept, and finally summarize the Airflow Dag Processing workflow and best practices.
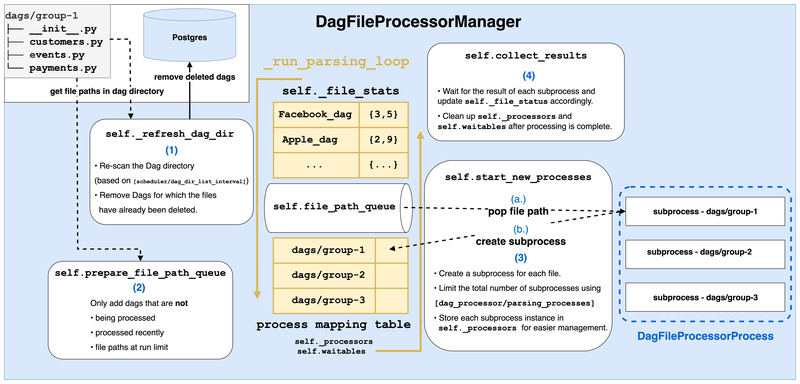
If it detects “files have been deleted”, it also updates self._file_paths, self._file_path_queue, self._file_stats through the previously mentioned set_file_paths
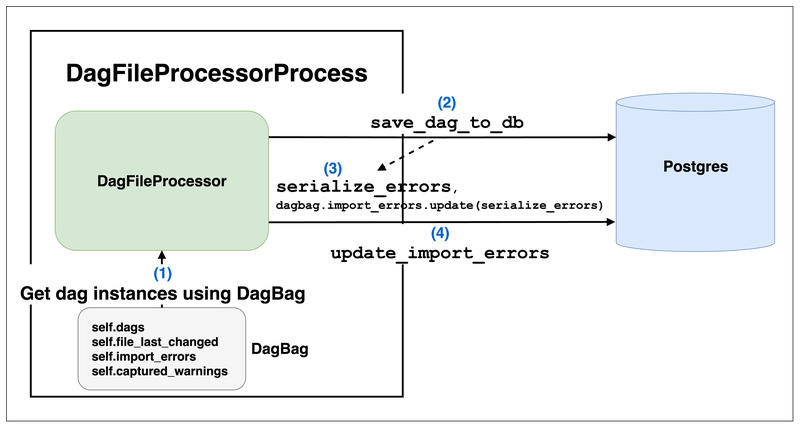
DagFileProcessorProcess uses DagBag to get the parsed Dags results for that path
_run_file_processor is the actual target function of DagFileProcessorProcess
Mainly executes dag_file_processor.process_file and returns tuple[number of dags found, count of import errors, last number of db queries] as self._result
DagBag is Airflow’s internal interface for finally reading Dag Files
Whether it’s the Dag Processor writing Dags to the Metadata DB
Or the Scheduler or API Server reading Dags
All go through DagBag to handle it, and DagBag’s constructor has a read_dags_from_db: bool option
For the Dag Processor: read_dags_from_db is always set to False, because the Dag Processor indeed needs to read Dags from Dag Files to synchronize Dag status
But for the Scheduler or API Server: read_dags_from_db is set to True, which ensures that Dags read in different deployments are consistent
And provides the following attributes for other Airflow components to use:
Summary: Best Practices Related to Dag Processing#
Through this article, we can understand the relationship between DagFileProcessorManager, DagFileProcessorProcess, and DagBag. Here are several key points I think are worth noting:
DagFileProcessorManager manages all Dag File paths to be parsed using a queue
Acts as a dispatcher and manages all DagFileProcessorProcess subprocesses
Each file path is handled by one DagFileProcessorProcess:
This process gets Dag instances and error messages through DagBag
This step is the most time and resource-intensive part!
A single Python file might contain just 1 Dag instance or potentially 1,000 Dag instances
And each Dag instance needs to undergo various checks!
And synchronizes this information to the Metadata DB
DagBag is the final interface for getting Dag instances: Whether Read-Only or Read-Write, all go through DagBag to obtain them
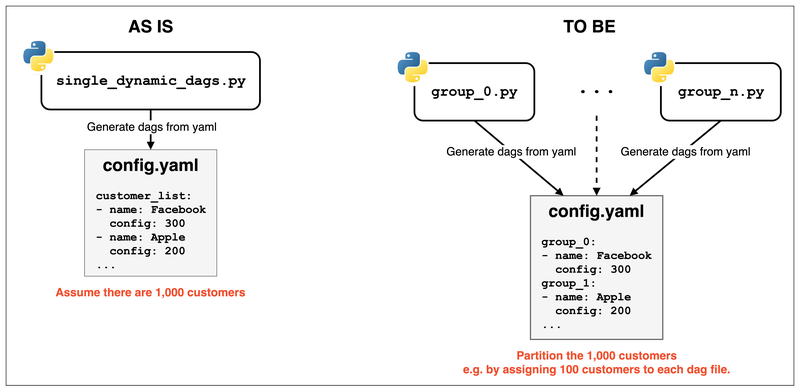
Best Practices for Generating Large Numbers of Dags Through Dynamic Dags#
Suppose there’s one Python file with only one Dynamic Dag that reads config.yaml And through config.yaml, it generates 1,000 different Dags
config.yaml can be any external state, like xxx.json Or a list generated by code, like a for loop
This approach causes these 1,000 Dag instances to be processed by only 1DagFileProcessorProcess
This also means This 1 process has to handle 1,000 Dag instances alone!
Because 1 Python file is handled by 1 DagFileProcessorProcess Airflow cannot predict in advance how many Dag instances this Python file will generate
This is one of the reasons why some Dags occasionally disappear suddenly when using Dynamic Dags to generate large numbers of Dags in a single Python file
For example: When loading the 800th Dag instance DagFileProcessorManager determines that DagFileProcessorProcess has been running too long and times out It directly terminates this process
Then proceeds to the next round of Dag Processing Causing the remaining 200 Dags to be judged as “deleted”! So you see 200 fewer Dags in the UI
But it’s possible that in the next round of Dag Processing, it doesn’t exceed the timeout And you can see all 1,000 Dags in the UI again
This creates the phenomenon of “Dags occasionally disappearing suddenly”
To avoid this problem simply use a partition approach
For example: Add grouping concepts to config.yaml and add some identical Python files to let different DagFileProcessorProcess instances handle different groups
Of course, you need another source_dag.py and partition.yaml configuration to maintain a single source of truth And let the CI/CD pipeline automatically generate these grouped Dag Files
# get the current group name from the file pathcurrent_file_name=os.path.basename(__file__)current_group=current_file_name.split('.')[0]# only import the customers for the current groupwithopen("config.yaml",'r')asf:customers=yaml.safe_load(f)[current_group]# generate the Dags for the current groupforcustomerincustomers:@dag(dag_id=f"{current_group}_{customer}_dag",start_date=datetime(2022,2,1))defdynamic_generated_dag():@taskdefprint_message(message):print(message)dynamic_generated_dag()
Exploring the AIP-82 External Event Driven Scheduling proposal in Airflow 3, the implementation details and use cases of the Common Message Queue, and how to enable real-time event-driven workflow scheduling in Airflow.