Apache Airflow – A platform to programmatically author, schedule, and monitor workflows
Apache Airflow is an open-source workflow management platform that enables developers to define data pipelines using the Workflow as Code paradigm.
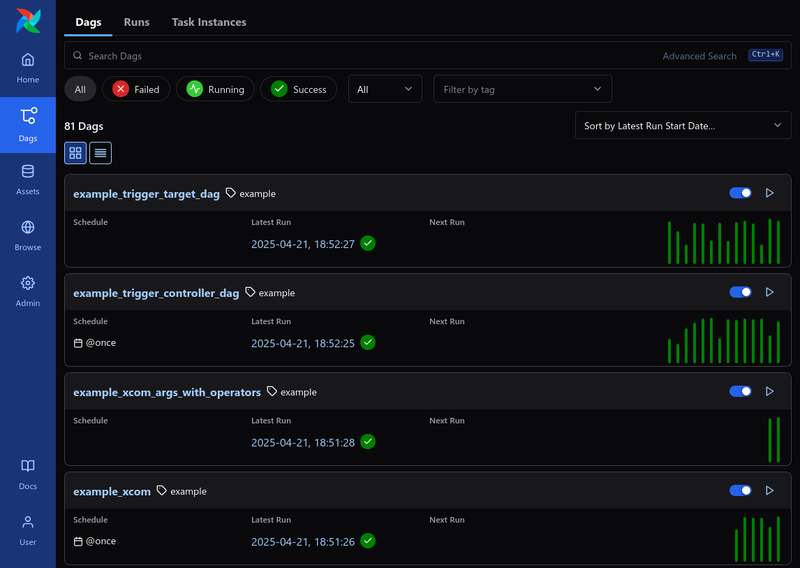
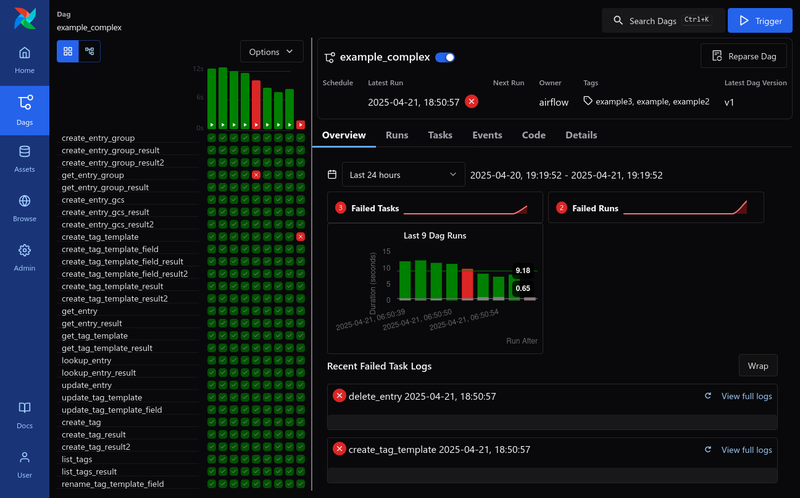
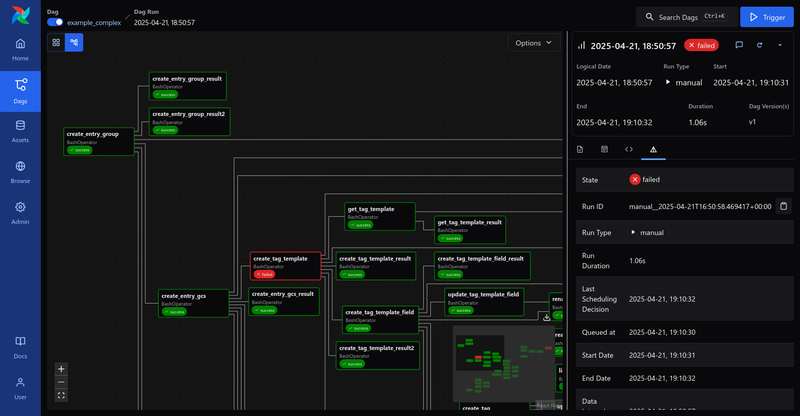
In Airflow, an entire workflow is called a DAG which stands for Directed Acyclic Graph.
A DAG consists of multiple Tasks and these DAGs or tasks can have various dependencies, as long as they do not form cycles.
Airflow supports various scheduling strategies and allows developers to define complex DAGs.
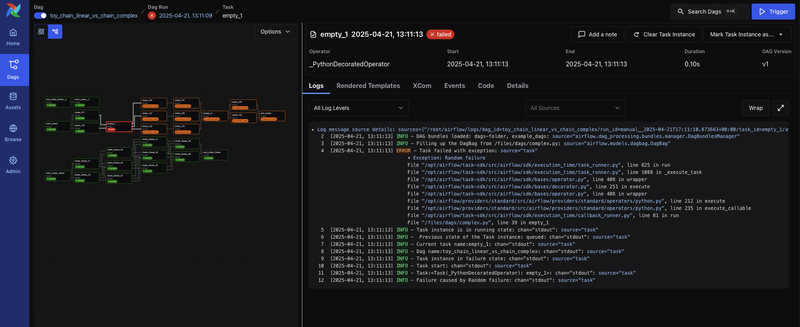
It also provides a comprehensive UI for monitoring and managing workflows.
Airflow is one of the most popular workflow orchestration tools today:
Over 40,000 stars on GitHub
The 5th largest project under the Apache Software Foundation
# Example code for Apache Airflowimportjsonimportpendulumfromairflow.sdkimportdag,task@dag(schedule=None,start_date=pendulum.datetime(2021,1,1,tz="UTC"),catchup=False,tags=["example"],)deftutorial_taskflow_api():"""
### TaskFlow API Tutorial Documentation
This is a simple data pipeline example which demonstrates the use of
the TaskFlow API using three simple tasks for Extract, Transform, and Load.
Documentation that goes along with the Airflow TaskFlow API tutorial is
located
[here](https://airflow.apache.org/docs/apache-airflow/stable/tutorial_taskflow_api.html)
"""@task()defextract():"""
#### Extract task
A simple Extract task to get data ready for the rest of the data
pipeline. In this case, getting data is simulated by reading from a
hardcoded JSON string.
"""data_string='{"1001": 301.27, "1002": 433.21, "1003": 502.22}'order_data_dict=json.loads(data_string)returnorder_data_dict@task(multiple_outputs=True)deftransform(order_data_dict:dict):"""
#### Transform task
A simple Transform task which takes in the collection of order data and
computes the total order value.
"""total_order_value=0forvalueinorder_data_dict.values():total_order_value+=valuereturn{"total_order_value":total_order_value}@task()defload(total_order_value:float):"""
#### Load task
A simple Load task which takes in the result of the Transform task and
instead of saving it to end user review, just prints it out.
"""print(f"Total order value is: {total_order_value:.2f}")order_data=extract()order_summary=transform(order_data)load(order_summary["total_order_value"])tutorial_taskflow_api()
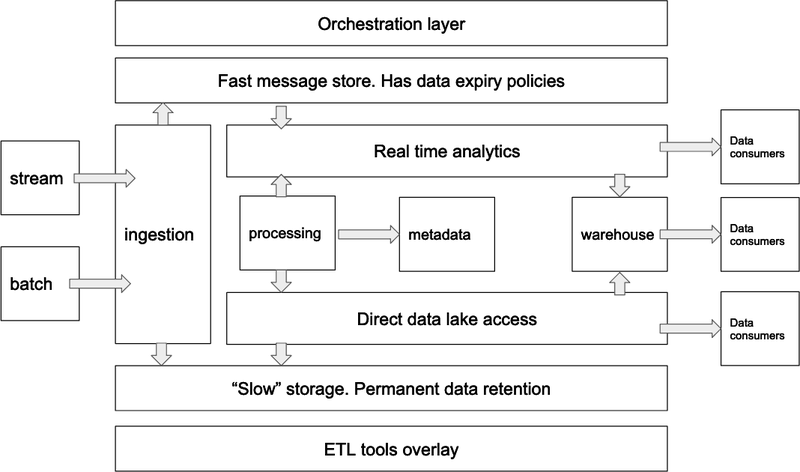
Airflow is often described as a Data Orchestration Tool.
In the context of a data platform architecture, Airflow functions as the orchestration layer—essentially the brain of the entire platform. It is responsible for precisely scheduling, coordinating, logging, and monitoring the status of every task within each workflow.
In large-scale data platforms, Airflow typically sits at the top layer, orchestrating every step from the data source all the way to the final data product delivered to end users. However, each individual task is usually executed by specialized tools dedicated to specific purposes.
For example:
An Airflow DAG might be responsible for periodically initiating data ingestion, then running ETL processes, and finally landing the data into the appropriate tables or views based on its type.
Within this process:
Data ingestion might be handled by tools like Airbyte
ETL might be processed by Spark, Flink, DuckDB, or other compute engines
Airflow’s focus is solely on orchestration
For small to medium-sized data platforms, using Airflow with LocalExecutor or CeleryExecutor is often more than sufficient!
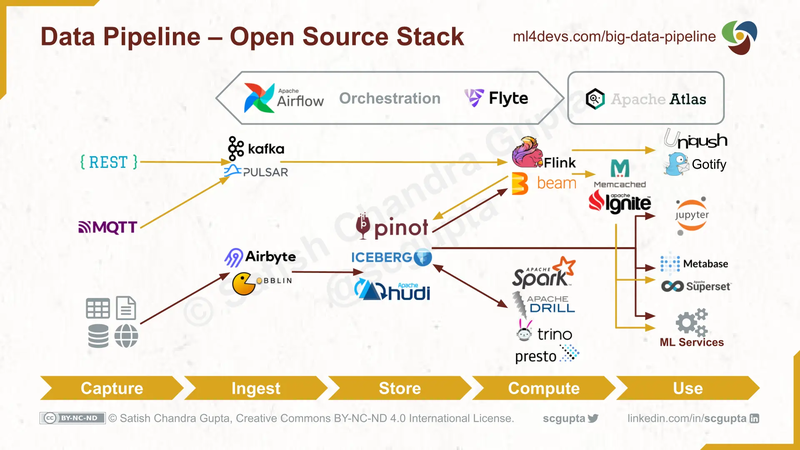
The relationship between Airflow and other common components of a data pipeline is illustrated below:
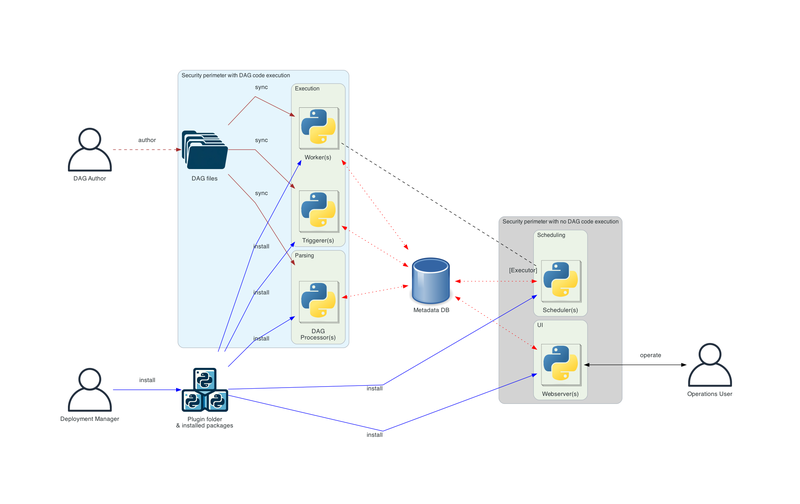
Based on the Airflow architecture diagram above, we can already infer the following:
The Meta Database I/O is the bottleneck of Airflow!
Every component constantly reads from and writes to the Meta Database. For example: each DagRun creates a new record; each TaskInstance creates another. These are continuously updated based on their execution status.
Therefore, Airflow is not suitable for:
Low-latency, event-driven workflows
Here, “low-latency” refers to millisecond-level execution.
As mentioned in the architecture, even with the Trigger component, the internal implementation involves polling the external system every few seconds.
Even if you use the REST API to trigger a DAG, the task still has to go through the Scheduler before being picked up by a Worker.
Consumers processing thousands to tens of thousands of messages per second
Currently, the maximum throughput of Airflow is approximately a little over 100 DAG runs per second.
Anti-pattern: Using a single Airflow cluster as a consumer downstream of RabbitMQ or Kafka. A single Airflow cluster is not suitable for handling thousands or tens of thousands of messages per second.
The emphasis on single cluster is important because: It’s possible to leverage the concept of partitions and use multiple Airflow clusters to handle different Kafka topics.
For example: airflow-cluster-a handles all messages from topic-group-a-* airflow-cluster-b handles all messages from topic-group-b-* …
By partitioning the workload, we can achieve Kafka-level message throughput while preserving the benefits of easy monitoring and manual retries at the DAG or Task level.
If your DAGs/Tasks require more compute resources, scale up to CeleryExecutor or KubernetesExecutor to distribute tasks across multiple workers, depending on your use case.
Let Airflow focus solely on its role as the orchestration layer.
Delegate actual task execution to specialized tools for each domain.
Fine-tune the Scheduler and Meta Database settings for performance and scalability.
Leverage Airflow’s built-in strengths to build a flexible, observable, and retryable data pipeline.
At the same time, it’s crucial to understand Airflow’s limitations:
For scenarios requiring low-latency (millisecond-level) or message throughput in the thousands to tens of thousands per second, Apache Airflow may not be the best fit.