
The cover is from the official
rocksdbdocumentation.
I came across the term Embedded Database recently, and I found them quite interesting. So I decided to write a blog post to share what I learned about them.
What is an Embedded Database?#
An embedded database is a DBMS that is tightly integrated into an application, running within the same process. Unlike traditional client-server databases, embedded databases do not require a separate server to manage queries and transactions. This makes them highly efficient for applications that need fast, local data storage without the overhead of network communication.
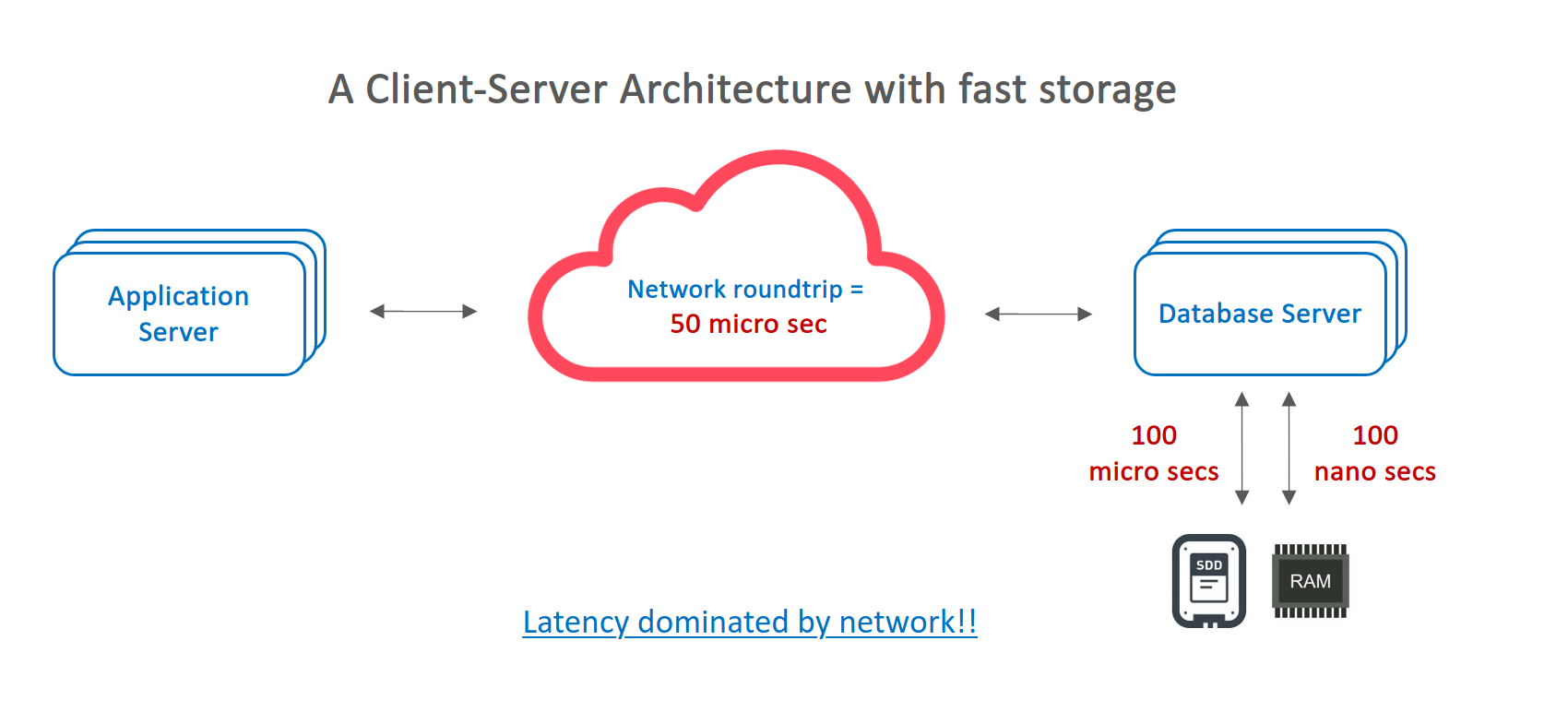
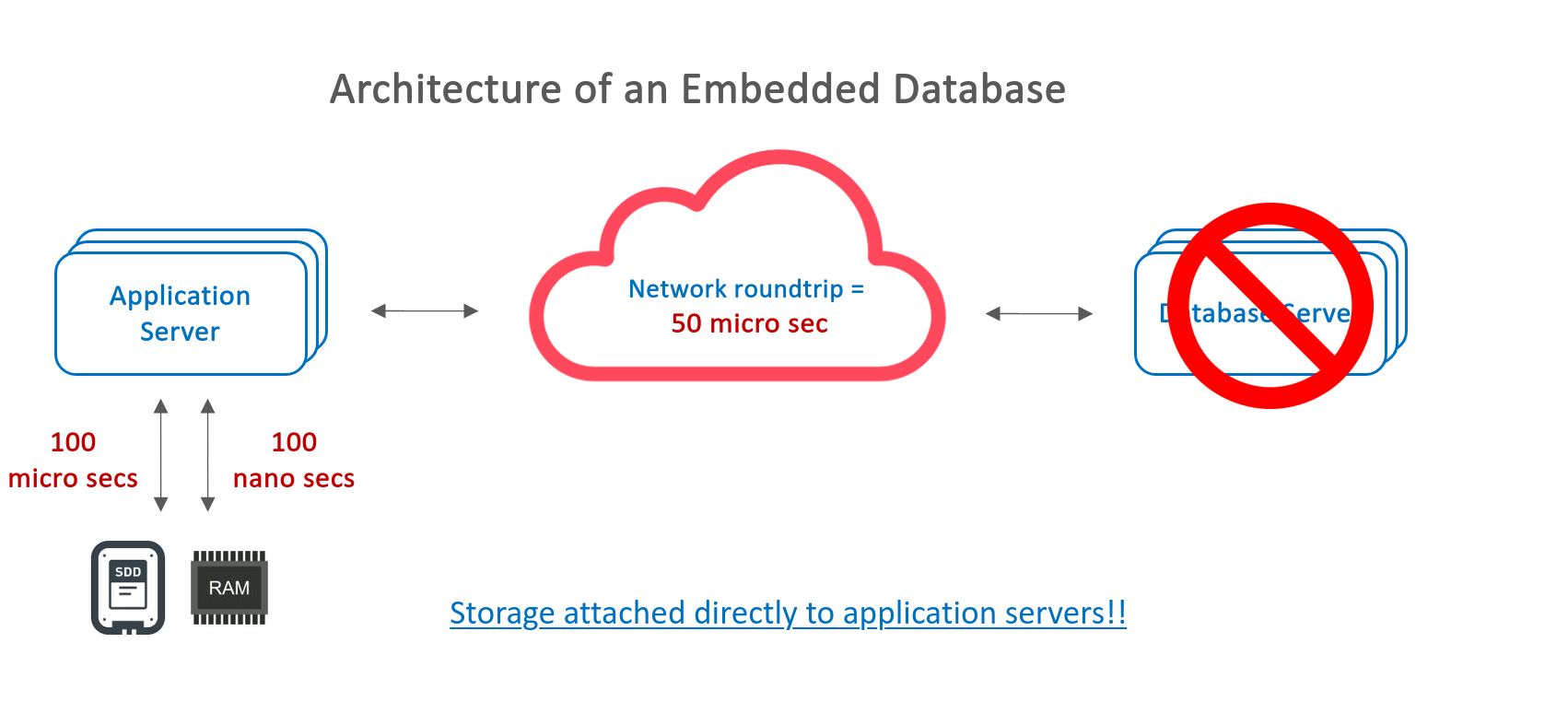
The above images is referenced from rocksdb-lab by @erhwenkuo
Introduction to RocksDB#
One of the most popular embedded databases today is RocksDB, an open-source, high-performance key-value store developed by Facebook. RocksDB is based on LevelDB but has been optimized for better write performance, lower latency, and high scalability.
Key Features of RocksDB#
- Log-Structured Merge (LSM) Trees: RocksDB uses LSM trees to optimize write operations and enable fast data ingestion.
- Optimized for SSDs: It takes advantage of modern SSD storage for efficient read/write operations.
- Configurable Compression: Supports multiple compression algorithms like Zstandard and Snappy to optimize storage.
- High Concurrency: Supports multiple read and write operations simultaneously without performance degradation.
- Point Lookups and Range Queries: Allows both individual key-value retrieval and efficient range scans.
Fault Tolerance in RocksDB#
RocksDB is designed to be resilient to failures and provides several features to ensure data durability and recovery:
- Write-Ahead Logging (WAL): Ensures data integrity by logging changes before they are committed.
- Snapshots: Enables point-in-time recovery by capturing the state of the database at a specific moment.
- Automatic Recovery: Upon restart, RocksDB can detect inconsistencies and recover data from the WAL.
- Replication: RocksDB can be configured for replication to provide higher availability in distributed systems.
Where is RocksDB Used?#
RocksDB is widely used in applications that require high-speed data processing and efficient storage solutions, most of them take RocksDB as a storage engine:
- Real-time streaming: Integrated into systems like Apache Kafka Streams for state management.
- Real-time stateful stream processing: Used in systems like Apache Flink for stateful stream processing.
- Distributed object storage: Used in systems like Apache Ozone for metadata storage in distributed object stores.
Example: Using RocksDB in Python#
Let’s look at a simple example of using RocksDB in Python to store and retrieve key-value pairs.
Note:
For RocksDB itself, it provides C++ and Java APIs, but for Python, you can use the rocksdict package, which provides a Pythonic interface to RocksDB.
Installation#
You can install Python bindings using uv:
uv pip install rocksdictSample Code#
import rocksdict
# Open a RocksDB database
db = rocksdict.Rdict("./testdb")
# Insert data
db[b"name"] = b"Alice"
db[b"age"] = b"25"
# Retrieve data
print(db[b"name"].decode()) # Output: Alice
print(db[b"age"].decode()) # Output: 25
# Close the database
db.close()More Operations with RocksDB#
RocksDB provides a rich set of operations for managing data efficiently:
- Snapshotting: Create a snapshot of the database to capture its state at a specific moment.
- Batch Writes: Perform multiple write operations atomically for better performance.
- Iterators: Traverse the key-value pairs in the database efficiently.
- Transactions: Ensure atomicity and consistency for multiple read and write operations.
- Column Families: Organize data into multiple column families for better data management.
- Statistics: Monitor the performance of the database using built-in statistics.
- Observability: Monitor the database using tools like Prometheus and Grafana for better insights.
For the above operations, you can refer to the rocksdb-lab for more details with hands-on examples in Java.





